
This blog post is a reworked chapter from my master thesis with the title “Site Reliability Engineering in a Transformative IT Landscape – Transitioning from Monolith to Microservices” at TUM submitted on the 15.12.2018. I wrote this thesis while working as an SRE at eGym in Munich, observing their technological transformation and how they applied SRE in practice.
Introducing a microservice landscape to an existing system is not only a challenge on the technical side. It especially requires a change of mind in the way our development processes works.
eGym already utilized agile processes for quite some time. There are small teams with a maximum of 6-8 people that are focused around certain aspects of the business. The way teams are set up, also affects the way the system architecture will eventually look like.
Organizations which design systems […] are constrained to produce designs which are copies of the communication structures of these organizations
Conway’s law
That statement is from the late 60s and even today perfect fits the microservice architecture paradigm. If we as an organization are destined to develop architectures that coincide with our communication structure, then we should organize our teams in a way that allows them to interact similarly.
eGym tries to not impose too much of a hierarchy following the Scrum methodology to have flat structures. Product owners decide the roadmap while within the teams tech-leads help the team prioritize the tasks to reach those goals. Tech-leads also sync in a daily meeting about progress and where problems arise in communication or their services.
On the non-technical side of the company there is a more hierarchical structure ranging from engineering managers to traditional C-levels. These structures are mostly separate from the tech teams and are not relevant for the development process itself. Most goals coming from management are fed into the development cycle through product owners and in such, there are little to no points of friction.
Silos
With microservices, we want to isolate each service as much as we can. We have previously discussed how the boundary for modules and services should be as strict as possible to guarantee that we do not leak business logic outside our microservice. Separation of teams and their responsibilities makes sense. Thus it is easier to match their tasks and services that they develop to one business context. However this also comes with the downside of sharing learnings between teams.
Let us assume that one team found a fantastic new way to achieve the same task with fewer resources – may that be developer time or resulting performance. When that team has no way to communicate this knowledge to other teams, the impact is much lower than what it potentially could have been.
We, for example, offer employees to take learning days, similar to holidays, that allow them to focus on a new technology or programming language. During that time they can gather new inspiration and explore new approaches to our daily challenges. The knowledge gained, can often be applied to the team that the employee works in. Unfortunately, none of the insights are usually shared with other teams by default.
Another way we try to exchange information are our labs. Those are a few consecutive days that everyone in engineering seeks to collaborate without the confines of our teams to solve problems within the whole company. Anyone can submit proposals for problems they see, and engineers organize a group to tackle those issues. While these might not always be solutions, that bring new insights to the company, they certainly allow for exchange between teams and solve relevant problems to increase the overall productivity.
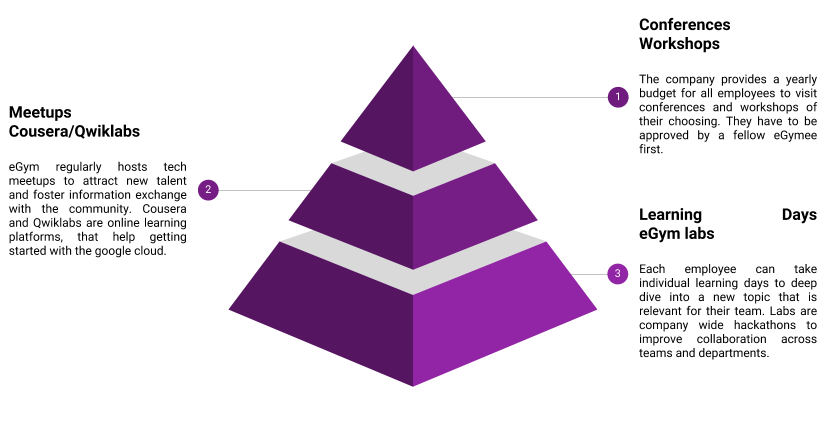
Finally, we offer our engineers to go to conferences and workshops. Funding is mostly provided in those cases, and a summary upon return is usually appreciated. Again not much of an in-depth exchange of the main takeaway happens, unfortunately.
Not sharing the knowledge gain efficiently and on a regular basis can effectively mean that multiple teams do the same work multiple times. For internal communication, we utilize Slack which offers us to discuss even more complex topics efficiently. Unfortunately, it is impossible to track all channels of all teams. Direct messages are usually not a problem, and one can inquire about specific topics at any given time which is certainly useful but overall not effective.
Essentially we have two requirements here that contradict each other. For our services we want a preferably strict separation of each service’s context, following Conway’s law would imply that we would need to enforce that strict separation for team communication as well not to risk leaking context boundaries. For the employees exchanging lessons learned is essential to avoid reinventing the wheel multiple times. We cannot satisfy both objectives, unfortunately, but need to think about how we can share fundamental knowledge in the best possible way.
Knowledge Sharing
Sharing insights is essential for mid-sized companies for which each investment into professional education of its employee is a critical money burden. Utilizing those investments and multiplying their impact by distributing that knowledge across employees could be beneficial.
Architecture Group
The architecture group discusses the big picture of the entire system. Each new service and technology is evaluated in this “open to everyone” forum. While participation is not mandatory, it would be good to have at least one person from each team to join in on these topics that are relevant for every team. There are a few permanent members that have been with the company almost from the start and know significant parts of the services that we operate.
The group not only facilitates discussions about the software architecture but also maintains the service inventory. The inventory keeps track of the core systems that we operate and that are business critical. It links to the relevant documentation for each of those services and provides basic monitoring. The group also decides on the adoption status of new technologies and programming languages.
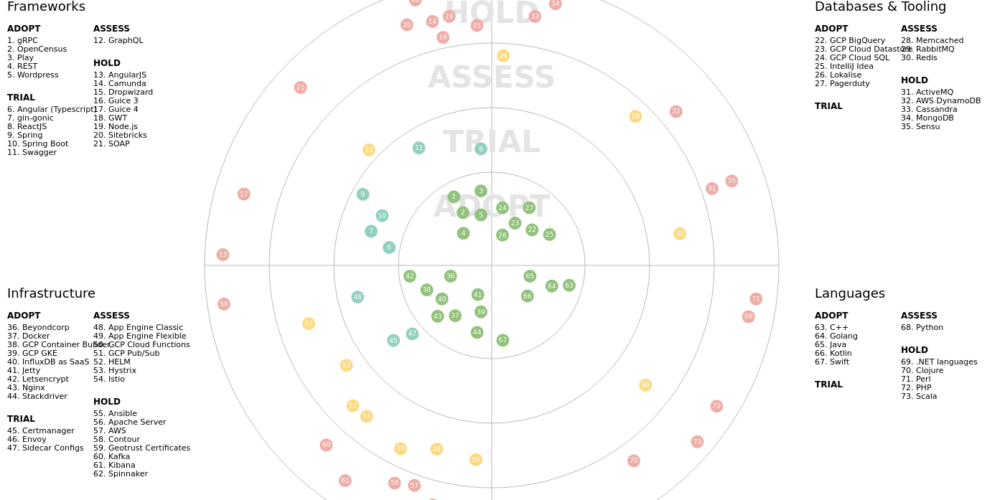
Tech Radar
In a so-called tech radar we track the grade to which specific technologies can be adopted or if they are still being evaluated.
The most inner circle points to technologies that we are actively using and should be considered for new services. The next ring shows technologies that are currently being tried out and are not yet fully considered to be used in production environments. The further out we go the less we should be relying on that specific technology and rather deprecate services that still make use of them.
The tech radar is furthermore divided into four sectors: frameworks, databases and tooling, coding languages and infrastructure.
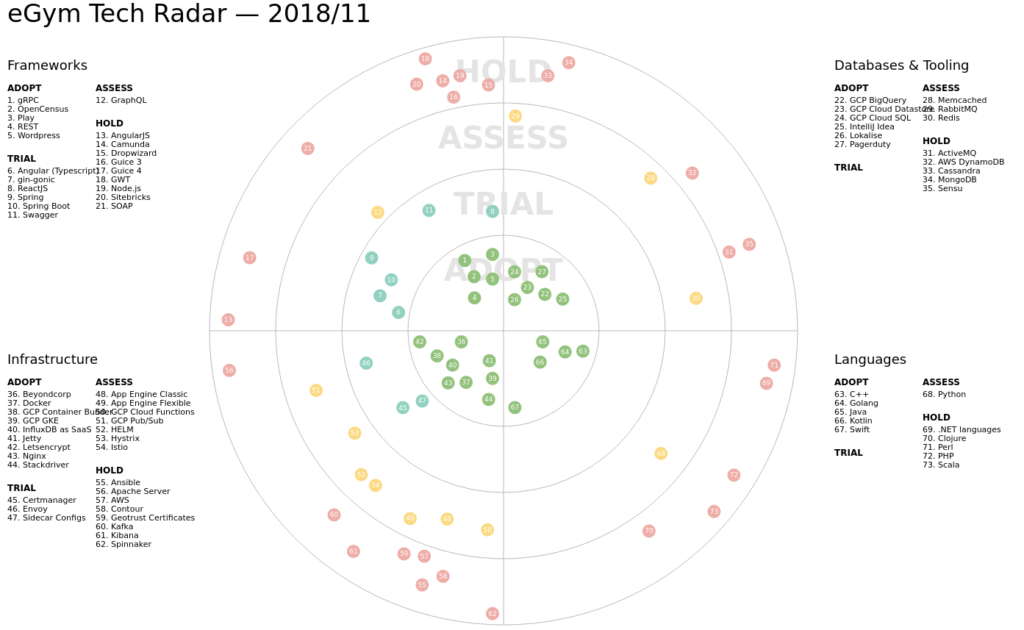
This gives every team enough flexibility to work with the proposed confines in terms of the tech stack but limits the level of expertise new hires have to bring along.
Before having the tech radar, services were written in a multitude of languages. Teams today have several legacy systems written in Scala, Python, and Clojure that need to be rewritten at some point in the future.
This is most relevant for the SRE team that needs to know the technology used in each service that they onboard. Reducing the number of distinct adopted technologies makes it easier to onboard new hires and lowers the overall complexity of our software architecture. Especially during incidents knowing the most common pitfalls can prevent longer debugging sessions and faster time to restore (TTR).
Cross Team Communication
A recent study has found that agile methodologies do help with in-team communication and sharing, but lack impact across teams and the whole organization. They also state that software engineers are motivated towards technically challenging and outcome-oriented topics over theoretical concepts.
While the main problem remains, that each team has their focus on the business division they are active in, the authors suggest that stronger extrinsic motivators could improve knowledge gaps across teams. This means that management needs to encourage participation in such
information exchange events actively.
In practice, this has also manifested at eGym in various ways. One of the problems encountered was that two teams would operate their own Kubernetes cluster with different ingress controllers. These clusters need to expose certain services to the internet employing an ingress controller.
While Kubernetes allows some rudimentary exposure of services by directly binding a particular port on the machine, this will not load balance any incoming requests. The ingress controller also provides additional merit like terminating Transport Layer Security (TLS) traffic and monitoring.
Kubernetes is very flexible in regard that it allows various implementation of ingress controllers to be operated and the APIs provide an easy interface to register them. Ingress controllers do have some complexity that they bring with them, as they rely on other services like the certificate-manager for the X.509 certificates to terminate TLS traffic. At some point one team decided to use nginx as their ingress controller while the other team went with contour.
Both are good options to chose and certainly have their merits but for SREs it meant, that we had to deal with both systems individually. Debugging problems required two methodologies and configurations were not compatible. We were not able to reuse already configured services in the other team and have invested significant time in debugging problems that have already been solved. Again, the technology radar helps and also the discussions in the architecture group lead to the decision to streamline the status quo and use the same ingress controller for both teams.
Overall eGym is already doing a few things to facilitate an exchange between teams, but it could be further improved. A best practice technology guide in addition to the tech radar might give useful guidance on common pitfalls when it comes to the used technologies. Further limiting the various technologies used throughout the company helps to have more experts in that stack for the eventuality of an outage. Participation in the architecture group could be increased by requiring at least one member from each team. That would keep all the teams on track with the latest decisions and would allow for better feedback from all teams on what the current critical architecture challenges are.